简单说下Mali G52核心的问题
gpu吧
全部回复
仅看楼主
level 13
还是那个小新💯
楼主
主要说一下核心
之前的G51的核心分为单像素核心和双像素核心
到了G52被取消了,相当于只有双像素核心了
G51的MP主要在单/双像素核心之间定制和选配
G52的MP在计算单元(execution engine)上定制和选配
每个核心可以在2组ee或者3组ee之间选配
每个ee的宽度从G51的4宽提升到了8宽
相当于是一组ee = 8 x ALU,那么一个G52核心 = 16或者24 x ALU
最初公布的时候G52最多只支持四个核心的选配
2019年07月19日 10点07分
1
level 11
花下语♋
嗯看不懂
2019年07月19日 14点07分
2
level 5
贴吧用户_0Ge45aE
写完了?
2019年07月19日 16点07分
3
level 11
mdzz微笑zz
没了?
2019年07月19日 18点07分
4
还是那个小新💯
可能更新也可能不更了
2019年07月22日 12点07分
一直很低调的猪
@还是那个小新💯
感谢
2020年02月07日 13点02分
level 13
暂时就叫这名了
有生之年
2019年07月19日 19点07分
5
一直很低调的猪
是的。。。。。。。。。
2020年02月07日 13点02分
level 12
zhu3536
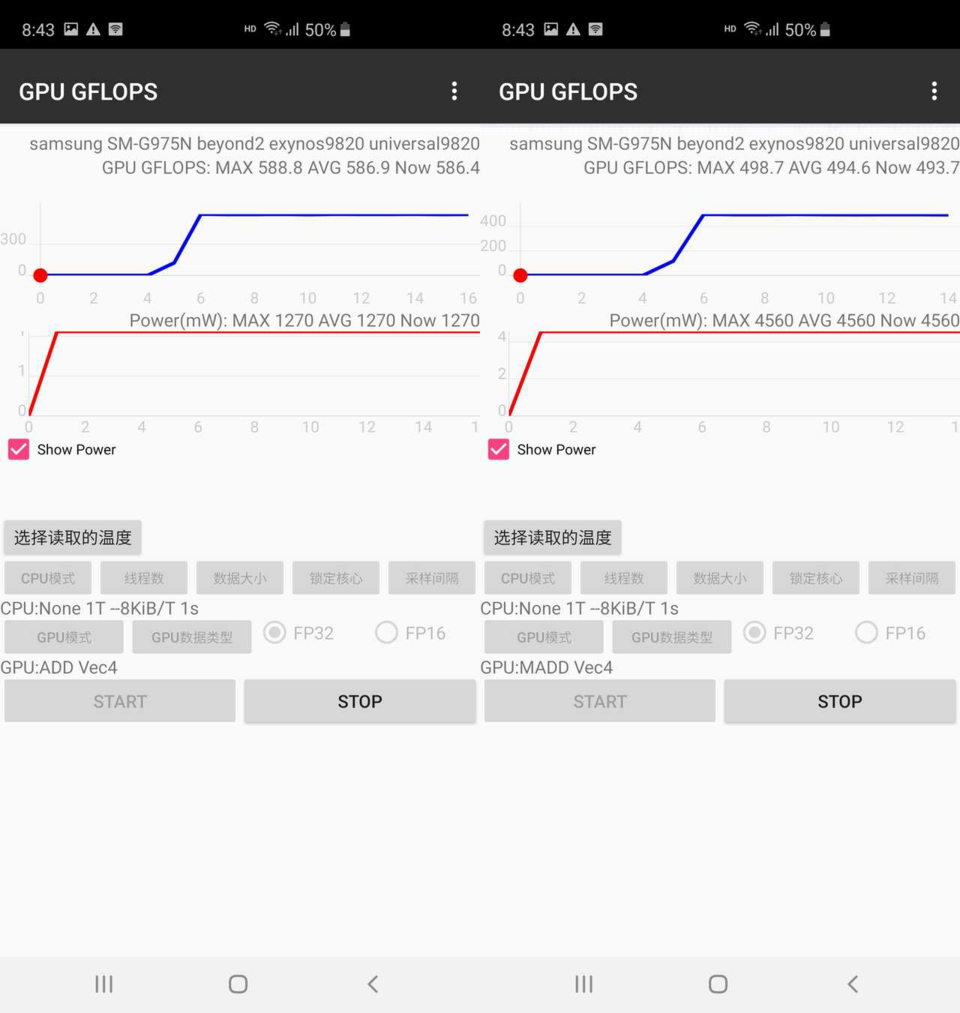
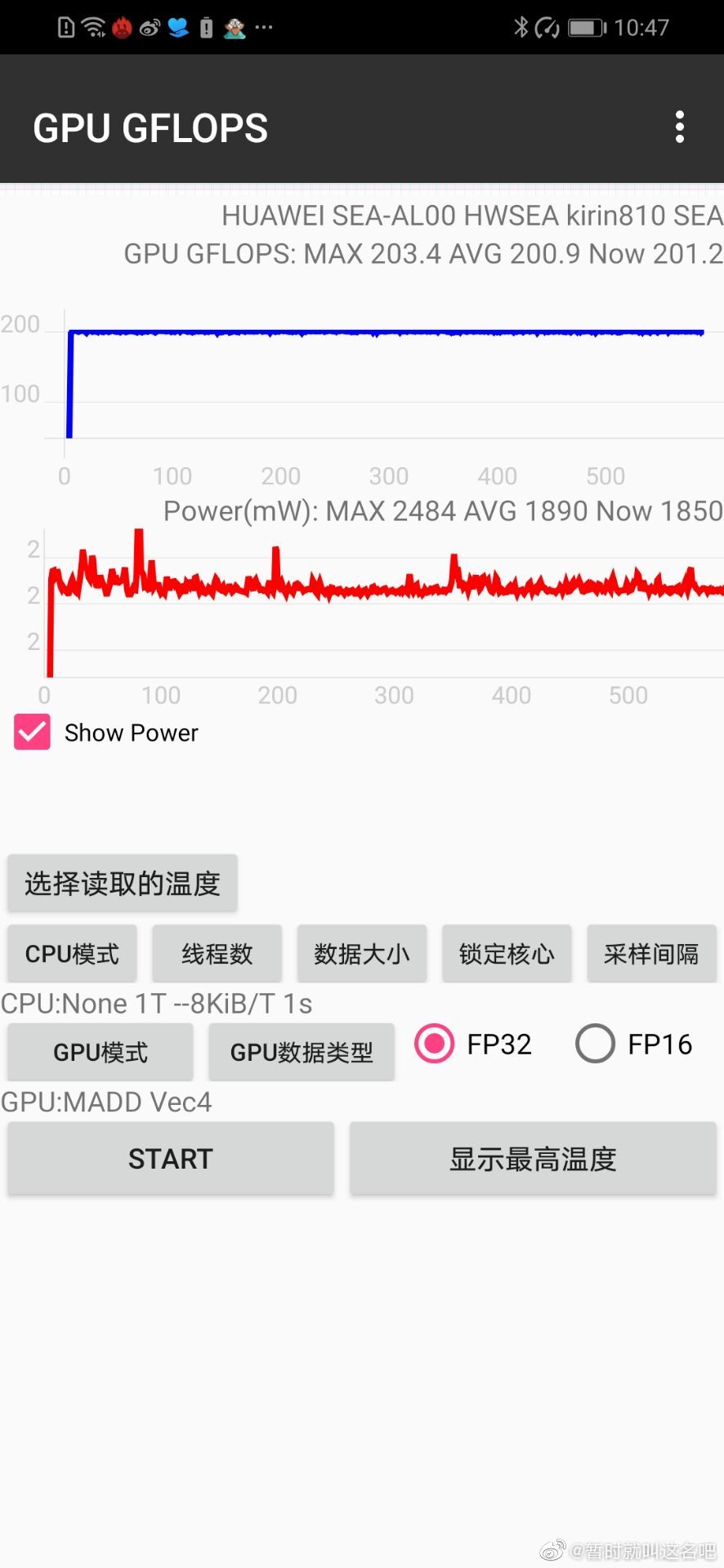
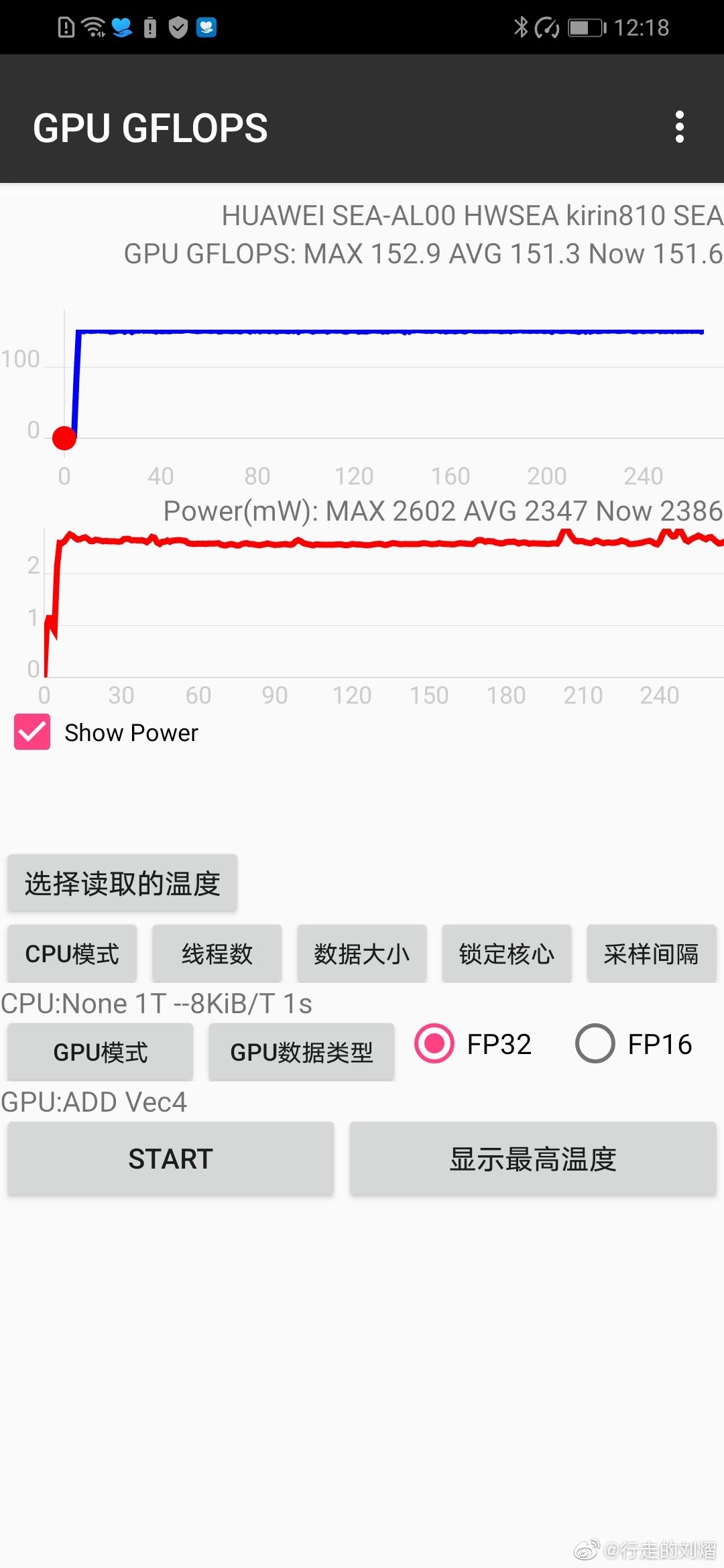
k810应该是2ee版6核g52。vec4 madd 203.4gflops,vec4 add 152.9gflops。bifrost每个ee的整数add/sfu已经证实是可以跑浮点add的。2*8*6*0.82*2 = 157.44gflops,效率152.9/157.44 = 97%。
bifrost一直以来有个现象,madd的浮点比理论值高。vec4、vec3、vec2、scalar效率逐渐降低,所以都以vec4 madd浮点来说明。g76mp10,不存在多出的madd的话理论浮点3*8*10*0.72*2 = 345.6gflops,实际435.3gflops,在345.6/3*4 =460.8gflops范围内,效率94% 。我认为多出的madd是一个核心多出来的,3ee的话多三分之一,2ee多二分之一。k810根据add浮点基本上确定是2ee版g52,16alu不可能多三分之一,不能整除3。按多二分之一算vec4 madd理论浮点16*6*0.82*2/2*3 = 236.16gflops,效率203.4/236.16 = 86%。3ee 6核不考虑多出的madd都有3*8*6*0.82*2 = 236.16gflops,实际值203.4低于这个值,和以前的3ee birost核心冲突;考虑多出三分之一madd 236.16/3*4 = 314.88gflops,差得更多。
2019年07月20日 05点07分
6
还是那个小新💯
看上去确实更像是2ee
2019年07月22日 16点07分
手活儿一天三次
96ALU就这么厉害
2019年07月23日 14点07分
level 12
zhu3536
2019年07月20日 05点07分
7
level 12
zhu3536
三星的g72和g76更厉害,add/sfu是arm ppt的2倍,华为的和arm ppt相符。9820 24x12x0.702x(1+2)=606.5288gflops。因为三星g72和g76的add多一倍,跑madd+add时才有add和多出的三分之一madd组合,24x12x0.702x3/3x4=808.704gflops。多出的madd跑fp32 add或者fp16时不起作用,比如9820的vec4 fp16 madd。
2019年07月20日 05点07分
8
ioncannon
这么神奇?
2019年08月02日 09点08分
jasonslg
GPU也有选配?
2019年07月20日 07点07分
还是那个小新💯
这样看,还是adreno架构上更稳,实际跑图形代码的时候好像基本没有mad+add的情况,多出来的add感觉没啥用。mali说是纯scalar架构,scalar效率这么低有点迷
2019年07月22日 12点07分
zhu3536
@ioncannon
这个在微博上和你说过。加个mul + add吧,640单跑vec4 fp32 乘、加,都能发出440G指令每秒,但跑madd就变成370G指令每秒了。而且乘和加的指令一样,乘的浮点多30%。
2019年08月02日 11点08分
level 5
霉族fg
那实际打游戏比980还差是什么问题?,有的游戏gt都没适配
2019年07月20日 09点07分
9
小額額
@霉族fg
810不是本來就比980弱吗?
2019年07月21日 03点07分
level 6
让我看看你的eu
大佬 ee是啥 4宽有是啥求解释
2019年07月21日 08点07分
10
还是那个小新💯
可以翻以前的mali介绍,吧里就有
2019年07月22日 12点07分
让我看看你的eu
@还是那个小新💯
大佬跑神的那个拷机软件madd和add是烤alu的吧
2019年08月02日 03点08分
level 11
贴吧用户_QPMSEE8
一句讲嗮,810目前中端芯片最强
2019年07月24日 11点07分
11
一直很低调的猪
是的
2019年08月11日 02点08分
一直很低调的猪
没有之一~无论是跑分还是长时间的负载
2019年08月11日 02点08分
level 12
zhu3536
用snapdragon profiler测了下540。gfxbench alu2利用fragment shader进行运算,有fp32和fp16指令,比例接近2:3,alu利用率80%,alu工作时间百分比94%。adreno的fp32和fp16是分开的,而且可以同时工作,但同时工作的效率不高。540的alu2数据,80G fp32指令每秒,130G fp16指令每秒。而跑vec4 fp32 madd 167G fp32指令每秒,330.9gflops浮点,跑vec4 fp16 madd 356G fp16指令每秒,675.5gflops浮点。
manhattan3.0和t-rex的读写总带宽在12GB/s左右,两者都有fp32和fp16指令。t-rex的fp16指令最多,占85%左右;manhattan3.0的fp32指令多一些,是fp16的2倍左右,不过有点不太稳定,有时候fp16指令数突然比fp32指令多好多。
以上说的有fp16指令的都是指fragment shader,vertex shader只用fp32不用fp16。
texturing 的读总带宽在8-9GB/s,写总带宽4GB/s头,总共12-13GB/s。linear filtered过滤92%,没分双线性和三线性,最近点采样1.7%,各向异性过滤0。
记得twy_2000测的980总带宽不超过9GB/s,比adreno5系需求的带宽少多了。
2019年07月25日 14点07分
12
还是那个小新💯
可以把各种主流的GPU的烤鸡情况总结成表格
2019年08月02日 08点08分
level 13
stevenplus105
我是这么想的,标准G71的一个ALU是MAD + ADD,一个EE有4路ALU,一个核有3 EE,但核里还有一个额外的特殊EE,这个EE有4路只能做FP32的MAD ALU。
G71的实际值超过理论值是因为这个额外EE,如果不算这个额外EE,每个ALU的理论值为(MADD 2,MUL 1,ADD 2,MADD+ADD 3),但是以效率最高的Vec4实际值为(FP32:MADD 2.5,MUL 1.2,ADD 1.9,MADD + ADD 2.8)(FP16:MADD 3.7,MUL 1.9,ADD 3.7,MADD + ADD 5.5),FP16吻合,但FP32不对。
算上这个只能做FP32 MAD的EE就合理了。
FP32:MADD 2*(3+1)/3=2.67,MUL (3+1)/3=1.33,ADD (6+1)/3=2.33,MADD + ADD还是3。</p>
<p dir="ltr">G52和G76同理,不管是2 EE还是3 EE,核里都还有1个额外的特殊EE,只是所有EE都变为8路ALU。
2019年07月30日 07点07分
14
level 6
让我看看你的eu
大佬gpu里的cu是啥
2020年01月16日 23点01分
17
1
2
尾页














![[乖]](/static/emoticons/u4e56.png)
![[滑稽]](/static/emoticons/u6ed1u7a3d.png)



![[惊哭]](/static/emoticons/u60cau54ed.png)

![[呵呵]](/static/emoticons/u5475u5475.png)