爬虫学习求助-关于网页源代码的标签
python吧
全部回复
仅看楼主
level 1
十年老兵申请出战!
楼主
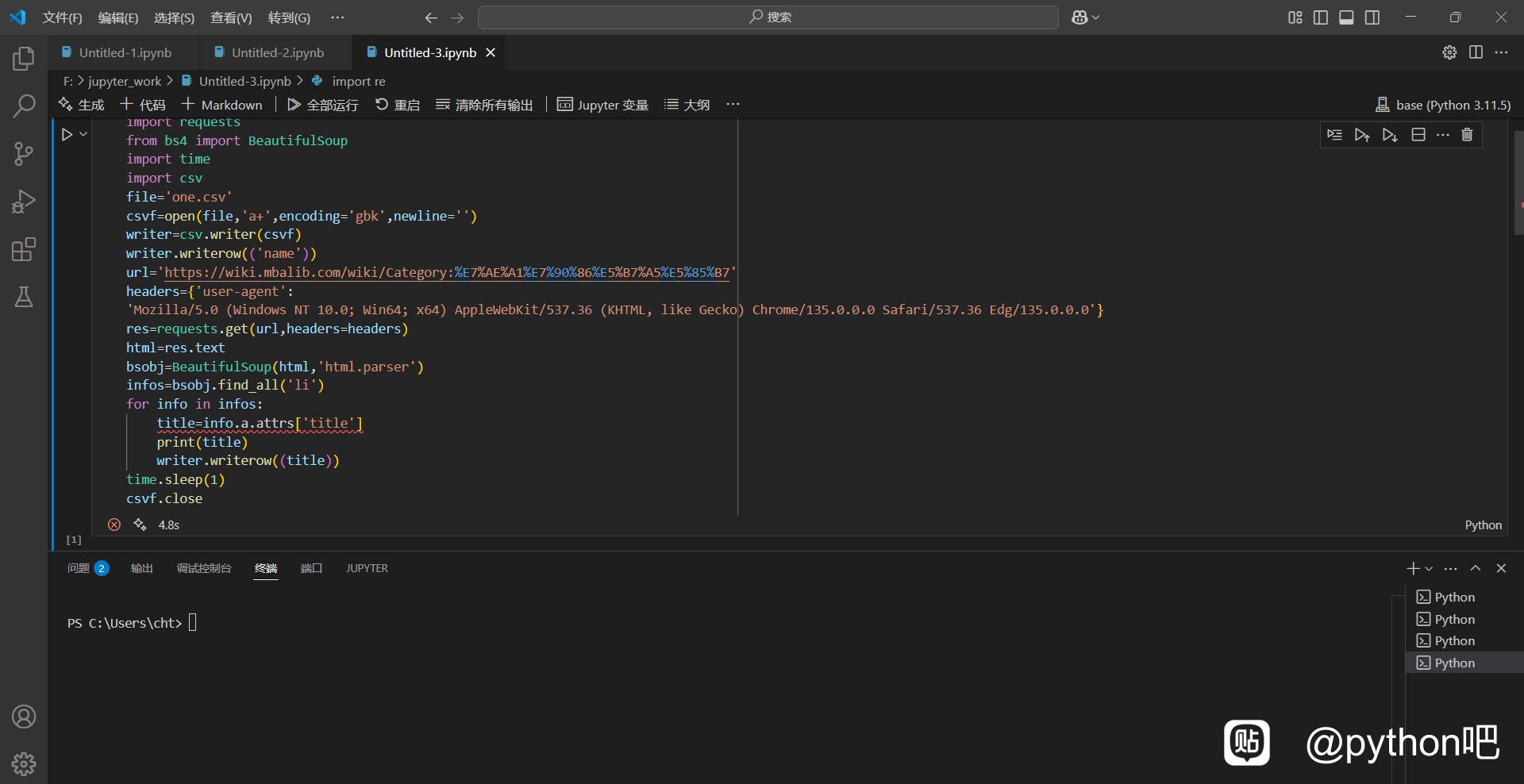
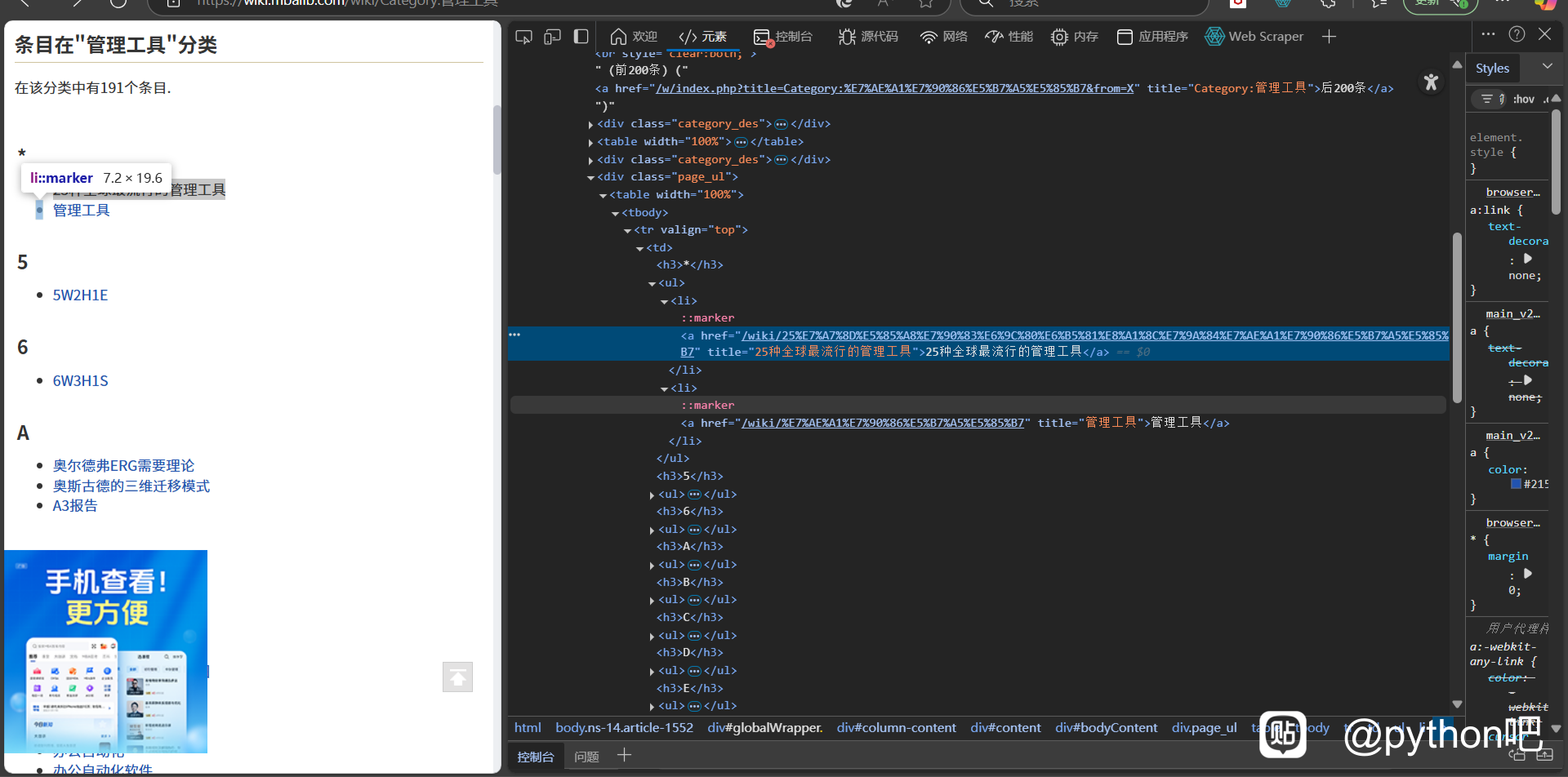
各位大佬好,我是一名初学小白,正在学习爬取网页信息,但是目前在爬取这个网页的信息时,爬取的是〈li〉标签的‘title’内容,代码也用的是title=info.a.attrs[lbk]title[rbk],为什么就是显示title这行报错呢?求大佬解答。谢谢大佬。
2025年05月04日 16点05分
1
level 2
狐火椛i
1. li不一定有a,a不一定有title,二者都要手动处理
2. 想明白具体要获取什么,查阅文档寻找更合理的调用。这里不是提取li,也不是a,而是li下包含title的a,具体代码自行提问大模型
2025年05月04日 23点05分
2
十年老兵申请出战!
谢谢你。
2025年05月05日 01点05分
1


![[小乖]](/static/emoticons/u5c0fu4e56.png)