SOVEREIGN讨论帖
laodar吧
全部回复
仅看楼主
level 5
大头萝莉2012
楼主
视频来自:
爱奇艺
2016年11月28日 14点11分
1
level 8
ieBugH
好久不见。最近在玩强化学习,自己写的不管是tabluar的还是NN参数化的Q-learning效果都好差,不管怎么调参数,在OpenAI gym里的'MountainCar-v0'这么简单的任务中都要好久才能取得较好的表现。难道是因为'MountainCar-v0'这个任务低谷吸引子太厉害?一般探索很难通关?
2016年11月28日 14点11分
2
大头萝莉2012
这个东西的reward延迟很长,你训练次数不够吧。自己编的还得保证没出现差错,可以先用极其简单的环境试试算法细节没写错。
2016年11月29日 04点11分
大头萝莉2012
看了SOVEREIGN对前半部分细节很失望,那个不能直接拿来用,是作者为了测试方便故意使用的某些手段(类似外挂了)
2016年11月29日 04点11分
ieBugH
@ieBugH
这个自带超时惩罚我没用
2016年11月29日 06点11分
大头萝莉2012
@ieBugH
前面说的我认同,这点上深有体会,但机器跑不动是不应该的,只要不是做超大规模的还是可以跑起来的。(用c与cuda设计的肯定能跑起来的)
2016年11月29日 08点11分
level 5
大头萝莉2012
楼主
图1
2016年11月29日 07点11分
3
level 5
大头萝莉2012
楼主
图2
2016年11月29日 07点11分
4
level 5
大头萝莉2012
楼主
图3
2016年11月29日 07点11分
5
level 5
大头萝莉2012
楼主
图4
2016年11月29日 07点11分
6
level 5
大头萝莉2012
楼主
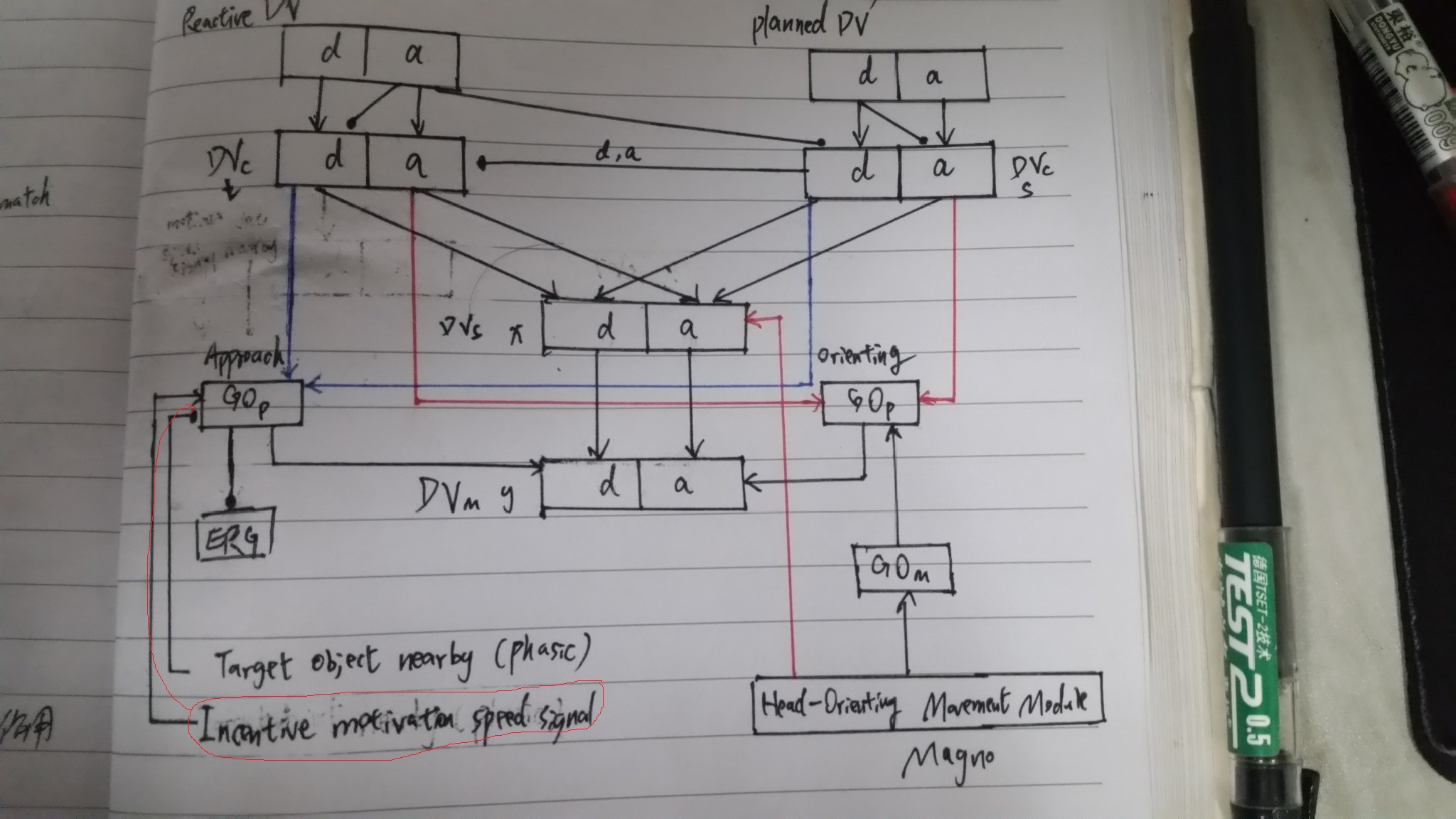
图5,就这个没看懂,根据ARTSCAN,motivation的不是从ita那里开始吗,很明显那是what线路,where只是reset作用。但这里为什么会是what与where decision,不是应该只有what decision吗,这个与ARTSCAN不符合啊
2016年11月29日 08点11分
7
ieBugH
where高层是视网膜坐标的认知地图表征,之后会和其它本体坐标映射,不排除最后还会和空间坐标的认知地图关联。 VAM就是指坐标/向量之间的映射/关联。
2016年11月29日 16点11分
ieBugH
reset是where流的曲面注意力坍塌导致的,只是where流的功能之一,所有和视觉位置相关的都归在where流里。
2016年11月29日 16点11分
ieBugH
https://en.wikipedia.org/wiki/Two-streams_hypothesis
2016年11月30日 11点11分
大头萝莉2012
@ieBugH
果然我少看了,那样的话where太亏了,就为了what服务。你说它和空间左边认知有关没问题,但这里为什么要motivated,难道对位置还有价值倾向???
2016年11月30日 15点11分
level 5
大头萝莉2012
楼主
正式问题
1 VAM Learning是什么
2 图2中的parvo和magno应该对应视网膜的大小细胞吧,左边是小,右边是大,图上标的很清楚,那中间的呢?
3 错误修改:2.5.4节内的2.7.3打印错误,应该是2.5.7。(应该是这样吧,我没理解错吧)
4 Drive representation为什么要放大parvo的信号
5 ART1,2,3是什么?
6 这里我们看到大多数网络全是以“对偶极子”出现的,为什么要这么设计,就不谈motivation里的必要性了,以前ARTSCAN里也是,从LGN开始就是了。
7 7楼中已提
2016年11月29日 08点11分
8
ieBugH
“对偶极子”有点类似于人工神经网络的偏置项,并且生物神经元无法有负的激活量,前馈权重也一般不是负的,抑制投射一般只能短程的。总之,抑制一般只起辅助作用,其权重一般不是用来表征记忆。因此所有模式都应转化为正激活量,正权重,进而需要对偶表征,有点类似电路里把两个半波整流拼起来。
2016年11月29日 16点11分
ieBugH
比如假设输入是灰度图,“亮”表征很容易由正权重实现,但是暗表征呢?什么样的正权重才能使输入越暗,暗表征激活量越大呢?解决这个问题就得需要偏置+竞争抑制,而这和对偶表征本质上是一回事,如在灰度图每个像素点表征亮的强度的同时有表征暗的强度的对偶表征,亮度实际上编码在它们的相对强度里。
2016年11月29日 16点11分
ieBugH
请在图中标出问题4的关键位置
2016年11月29日 16点11分
ieBugH
DIRECT看过了没,坐标积分和变换理解了没
2016年11月30日 09点11分
level 5
大头萝莉2012
楼主
这个模型应该可以看成ts+mv+dv+artscan的缩小版
2016年11月29日 15点11分
9
level 5
大头萝莉2012
楼主
图上细小的红线指出的就是放大parvo的根源,原文的意思大体是这样的:incentive motivational signal放大了GOp信号,目的是增大parvo的输入信号,incentive motivational signal就是drive那里的。
2016年11月30日 14点11分
10
level 5
大头萝莉2012
楼主
出现了几个新问题
1.图2的parvo是走what路线,那mango走的什么?中间的是where路线,那它属于parvo还是mango,另外如何从这个图中看出ARTSCAN的对应的部件?
2.mango路线中开始的是ubdirectional transient cell,这个作者在式子里表示的是bij,把它输入给一个directiional中间神经元,这个作者用式子表示的是cij_R/L(左右还互相伤害),很明显到这个变成了左右两个,这让人联想到了双目的左右,但很明显这里开始输入的就是单目的图hij,输入顺序是hij-》bij-》cij_R/L,那么这里的分成左右该怎么很好的解释呢?
@ieBugH
2016年12月08日 09点12分
11
大头萝莉2012
总的来说对mango这条路很迷茫
2016年12月08日 09点12分
大头萝莉2012
我觉得我哪里理解错了,从cij开始就把单幅图片bij分成了两个,应该这么理解,那么这么分的话在这里是直接平方一半,还是有重叠部分的分?
2016年12月08日 10点12分
大头萝莉2012
@ieBugH
好吧,这个暂时放在这儿吧
2016年12月15日 07点12分
大头萝莉2012
@ieBugH
本来看这篇目的是因为他那个视频有点吸引人,以为这个小模型可以直接拷贝,结果还是玩实验,但现在目的就是通过它看看我漏了什么,看他论文的目的也就想了解下大脑一种可能运行的机理(从之前结果看这个可能性很高,细节除外)
2016年12月15日 14点12分
level 5
大头萝莉2012
楼主
3.Motor Working Memory and Planning System,这个是motor的motivationally-reinforced,也就是说motivation有两个,一个是目标物的,一个是motor的,那么这个motor的motivation是否对照telos下面的BG那块?
2016年12月08日 11点12分
13
大头萝莉2012
我可否把NET+DV+motivationally motor=telos里从FEF向后的所有东西?
@ieBugH
2016年12月08日 11点12分
1



![[狂汗]](/static/emoticons/u72c2u6c57.png)