【水】【转】为什么机器能够学习?
人工智能吧
全部回复
仅看楼主
level 13
Bz_______
楼主
2016年03月01日 13点03分
1
level 13
Bz_______
楼主
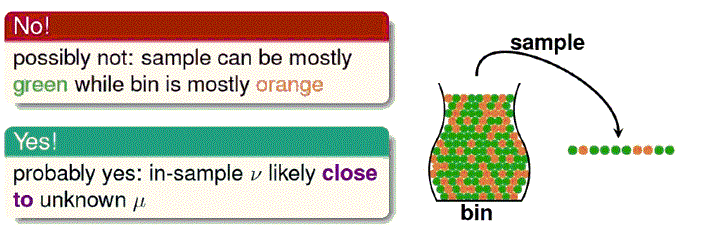
考虑一个罐子,里面装着橙色和绿色的弹珠。如何估计里面的橙色弹珠比例?
一种方法是抽样。如果样本大小为N,样本中橙色弹珠比例为ν,而罐子中橙色弹珠比例为μ.
ν反应了μ的哪些信息?
2016年03月01日 13点03分
2
level 13
Bz_______
楼主
存在着样本比例ν很低而实际比例μ很高的情况,所以不
总能根据ν的值推断μ的值。
2016年03月01日 13点03分
3
level 13
Bz_______
楼主
Hoeffding不等式指出,在样本N足够大时,误差|ν-μ|的会足够小。因此概率上还是可以根据ν的值推断μ的值的。
2016年03月01日 13点03分
4
Bz_______
误差|ν-μ|会足够小
2016年03月01日 13点03分
level 13
Bz_______
楼主
如果将橙色弹珠看做机器学习算法的“分类错误”,绿色弹珠看做机器学习算法的“分类正确”,罐子看做全部数据,N看做训练数据,则可以由Hoeffding不等式得到这样的推论:
训练样本足够大时,训练数据上的结果与全部数据上的结果会足够接近。
这就是机器学习为什么能“举一反三”的理论基础。
2016年03月01日 13点03分
5
Bz_______
另一个重要前提是“训练数据是从全部数据中随机选取的”。
2016年03月01日 13点03分
level 13
Bz_______
楼主
如果M小n大,P(|ν-μ|>ε)(总体)≤2Mexp(-2ε²n),我们就有信心认为训练样本全对的模型在全部样本上几乎全对,也就是泛化能力足够强。这也就是简单的模型(M小)更容易被人们所接受的原因。
2016年03月01日 14点03分
7
level 13
Bz_______
楼主
来源:
https://class.coursera.org/ntumlone-003/lecture
2016年03月01日 14点03分
8
Bz_______
第四讲: Feasibility of Learning
2016年03月01日 14点03分
level 13
Bz_______
楼主
这个证明对于无监督学习是否还是
正确的
?
2016年03月02日 09点03分
9
level 9
飞行于天
其实我并没有看懂,但是我有一些疑问。你说的这种学习方式是建立在一种评价方法上的吗?如果是,那么我想问一种评价方法足以准确的衡量我们所处的,多变的世界吗?如果不能够准确的衡量是不是就意味着无法精确的感知?那么没有精确的感知还能够建立起精确的运行规律吗?不能建立起精确的世界运行规律是不是就意味着智能是不完善的呢?
我觉得人的智能来自于对事物发展规律的认识,而认识的基础是不断完善的评价体系,而人类的评价体系由经过自然选择后的基因遗传来逐步完善的。
2016年03月02日 13点03分
10
Bz_______
这种学习方式建立在对数据的正确预测上。
2016年03月03日 02点03分
Bz_______
这种评价方式对于智能是极其不完善的
2016年03月03日 02点03分
飞行于天
@Bz_______
这样看来你我没有太大分歧,智能需要更全面的评价体系,而能够根据自然选择而做出变化,并进一步形成新的评价体系是很重要的。再说我的观点:自编程可以用来分解,组合现有评价体系形成新的评价体系。当下要做的是开发符合自编程原则的评价型小程序。
2016年03月03日 06点03分
1