
level 1
黑木起龟
楼主
无损音乐和有损音乐的概念大家应该都非常清楚,我也不多废话。
虽然大家都知道有损音乐损失了音质,但是对于究竟损失了什么,没有多少人有了解
有损音乐在保证了一定音质的情况下又大幅度减少了文件体积,肯定是按照某个规律来进行的,如果随便删减信息肯定会有很大失真。
于是本文就来简单介绍一下有损音乐的“损失”规律
要了解有损音乐的损失内容,我们需要先了解一些人耳听觉的特性
首先,简单的介绍一下听觉掩蔽效应
掩蔽效应可以归类为三种:绝对掩蔽,时域掩蔽,频域掩蔽
要了解有损音乐的损失内容,我们需要先了解一些人耳听觉的特性
首先,简单的介绍一下听觉掩蔽效应
掩蔽效应可以归类为三种:绝对掩蔽,时域掩蔽,频域掩蔽
1.绝对掩蔽
人的听觉系统对于声音频率信号的感知范围从20Hz~20kHz,在此频率范围内的声音信号,只要能量足够大,就能被人的听觉系统捕获。对于每个频率的信号
而言,存在着一个相应的听觉阈值。在没有任何其他噪音干扰的条件下,某一频率的信号的能量大于其相应的听觉阈值,那么这个信号才能够被听到。
上面的说法可能比较繁琐,简单的来说,就是声音必须达到了某一个最小强度,才能够被人听到,没有达到这个最小强度的声音,人是听不到的。不同频率
的声音的这个最小强度不同。
于是,我们可以通过实验把不同频率的这个最小强度都测试出来,然后画在一张图上,就得到了人耳可听最小响度曲线
 这个最小响度曲线只表明了人耳可听最低的限度,现在让我们用同样的思维方式思考一下。如果要让人耳对于几个不同频率的声音感受到的响度一样,这些频率的声音要达到多少强度呢??
这个最小响度曲线只表明了人耳可听最低的限度,现在让我们用同样的思维方式思考一下。如果要让人耳对于几个不同频率的声音感受到的响度一样,这些频率的声音要达到多少强度呢??
当然,这也是可以通过实验测试出来的,综合数据,画在一个图内,又可以得出一条曲线。我们把多个不同响度的曲线放进一张图内,就是常说的等响曲线图了
 一般取听觉响度为40方的这条曲线当作参考,把这条曲线倒置,就是常用的A计权网络(A声级),实践证明,不论噪声强度高还是低,A计权都能很好的反映人对噪声响度和吵闹的感觉;而且,A计权同人耳的听力损伤程度也能够对应的很好,即A声级越高,损伤也越严重。我们经常看到的耳机或者是音箱的频响曲线,都是经过A计权处理后的曲线,如果你看到哪个的曲线是很平直没有什么起伏的(特别是在高频),那么这条曲线就很可能是没有经过计权的曲线了,和实际的听感差距会很大,不能够当作参考标准。
一般取听觉响度为40方的这条曲线当作参考,把这条曲线倒置,就是常用的A计权网络(A声级),实践证明,不论噪声强度高还是低,A计权都能很好的反映人对噪声响度和吵闹的感觉;而且,A计权同人耳的听力损伤程度也能够对应的很好,即A声级越高,损伤也越严重。我们经常看到的耳机或者是音箱的频响曲线,都是经过A计权处理后的曲线,如果你看到哪个的曲线是很平直没有什么起伏的(特别是在高频),那么这条曲线就很可能是没有经过计权的曲线了,和实际的听感差距会很大,不能够当作参考标准。
需要注意的是,等响曲线只是实验室测量少数人得出的结果。不同人的身体条件不同,对于声音的感受能力也不同,所以大部分人的听觉特征不会完全吻合等响曲线,但是大致的走向会是基本一样的,误差也不会太多。
2.时域掩蔽
时域掩蔽指的是能量较强的声音信号可以掩蔽其前或其后或同时出现的能量较弱的音频信号的现象。对于其前的声音信号的掩蔽称为超前掩蔽,其后出现的信号的掩蔽称为滞后掩蔽,同时出现的信号的掩蔽称为即时掩蔽。
即时掩蔽的作用时间与掩蔽信号的持续时间一样长,而超前掩蔽与滞后掩蔽则是即时掩蔽在时间上的延伸效果。在时间线上,越向两端延伸,效果的程度越弱。
按照常理,后出现的信号对于先出现的信号是没有掩蔽作用的,但是由于人的听觉系统还有大脑的反应滞后以及声音信号前后的关联性,使超前掩蔽也会出现。
超前掩蔽的作用时间一般很短,在20ms左右,而之后掩蔽的作用时间可以持续150ms。
举个栗子,日常生活中谈话时,如果旁边的汽车突然响起断续的鸣笛声,我们也会听不清楚对方的谈话内容
时域掩蔽主要是因为听觉系统和大脑对于声音的反应滞后产生的,所以和上面的绝对掩蔽相同,不同人的大脑反应速度不同,所以掩蔽的持续时间也不会一样
3.频域掩蔽
一个强纯音会掩蔽其附近频率同时发声的弱纯音,这种特性称为频域掩蔽。频域掩蔽就是时域掩蔽中的即时掩蔽,只是它是在频域中之研究掩蔽效应。
为了能方便理解,这里举例说明。如果一个1000Hz的纯音比另一个900Hz的纯音响度高18dB,那么900Hz的音将被1000Hz的音掩蔽,但是如果要让这个1000Hz的纯音去遮蔽距离较远的1800Hz的一个纯音的话,那么1000Hz音就必须要高出1800Hz的音45dB!实际情况下听到的声音中比较少碰到这种高出45dB的情况,频域的掩蔽效应主要集中体现在附近的频率上。
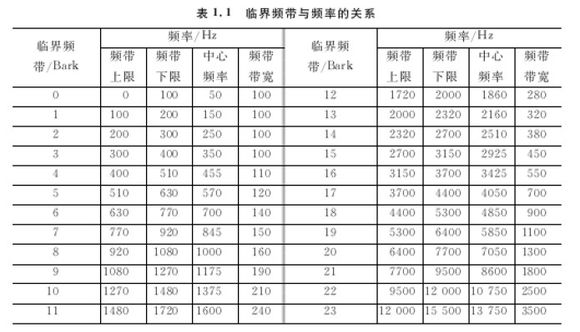
通过深入的研究实验发现,掩蔽阈值在以掩蔽信号频率为中心的一个狭小频带内是一个常数,这个狭小频带就被称为以该信号位中心的临界频带。临界频带的带宽随着中心频率的变化而变化,掩蔽效应也随之变化,这种变化是非线性的,而非线性关系在研究和表达上很不方便。研究者们使用了一个经验公式来解决这个问题,掩蔽曲线与临界频带的关系变成了线性关系。这个公式比较复杂这里就不做论述。
 其实大家理解了上面三个概念以后,不难想象到有损音乐是如何对“无损”音乐进行缩减而又保持一定的音质的
其实大家理解了上面三个概念以后,不难想象到有损音乐是如何对“无损”音乐进行缩减而又保持一定的音质的
研究者们综合以上三个掩蔽效应,再加上一些其他因素,建立起了一个数学模型,人体听觉心理学模型(PerceptualModel)
在MP3的编码过程中,通过使用听觉心理学模型对原始无损信号进行计算,滤除掉理论上会因为掩蔽效应而听不见的信号,只留下那些会被听到的信号,这一过程就是“有损”的过程了。
有损音乐“损失”的就是上面提到的三种会被掩蔽掉的信号
通过对心理学模型的精度进行调整,可以不同程度地滤除掉信号,滤除的信号多了,虽然能减少总信息量节约空间,但是势必会造成较大的失真。
MP3的编码过程中,以CBR(固定码率)为例,规定一个数据流量(比如常见的320k
bp
s),然后从最高精度的心理学模型开始试起,进行编码,得出一个结果,然后判断这个结果的数据流量是否超过了规定的流量,如果超过了,则换下一个模型进行编码,滤除更多的信号进行尝试,知道数据流量符合规定流量。MP3编码就是这样不停地进行try and error。
MP3的编码过程还有很多很多,多相滤波分频带,子带分别输出样本,数据流包装成帧,Huffman编码进一步压缩体积。。。。等等等等
前面也说了,本文只是向大家介绍有损和无损的差别,对于这些涉及算法的知识,只能请大家自行搜索相关知识了
最后,我想说的是,不同人对于声音的感知能力不同,听觉心理学模型不能满足所有人,只能取一个居中的模型。如果某人对声音的感知能力超过了这个模型的预期,那么他就有可能听出“有损”和“无损”的差别来了。要区别出有损和无损的差别对回放设备也有要求,如果你的回放设备解码能力不佳,放大部分失真不够低,电声转换部分又有一个较大失真的话,经过这几层失真,无论原始信号是什么,等你听到都变成“有损”了,无论你听觉能力多好,也是无法分辨出无损和有损的差别的。
声音的感受能力是可以进行训练的,个人经验,就上面的时域掩蔽来说,一个训练有素的鼓手的听觉时域掩蔽效应的影响肯定不会有普通人那么大。
就欣赏音乐的角度而言,我们没有必要去刻意进行这种训练,但是我们要知道,不能因为自己听不出音质的还坏就认为别人也没有能力听出音质好坏
2014年12月02日 11点12分
1
虽然大家都知道有损音乐损失了音质,但是对于究竟损失了什么,没有多少人有了解
有损音乐在保证了一定音质的情况下又大幅度减少了文件体积,肯定是按照某个规律来进行的,如果随便删减信息肯定会有很大失真。
于是本文就来简单介绍一下有损音乐的“损失”规律
要了解有损音乐的损失内容,我们需要先了解一些人耳听觉的特性
首先,简单的介绍一下听觉掩蔽效应
掩蔽效应可以归类为三种:绝对掩蔽,时域掩蔽,频域掩蔽
要了解有损音乐的损失内容,我们需要先了解一些人耳听觉的特性
首先,简单的介绍一下听觉掩蔽效应
掩蔽效应可以归类为三种:绝对掩蔽,时域掩蔽,频域掩蔽
1.绝对掩蔽
人的听觉系统对于声音频率信号的感知范围从20Hz~20kHz,在此频率范围内的声音信号,只要能量足够大,就能被人的听觉系统捕获。对于每个频率的信号
而言,存在着一个相应的听觉阈值。在没有任何其他噪音干扰的条件下,某一频率的信号的能量大于其相应的听觉阈值,那么这个信号才能够被听到。
上面的说法可能比较繁琐,简单的来说,就是声音必须达到了某一个最小强度,才能够被人听到,没有达到这个最小强度的声音,人是听不到的。不同频率
的声音的这个最小强度不同。
于是,我们可以通过实验把不同频率的这个最小强度都测试出来,然后画在一张图上,就得到了人耳可听最小响度曲线
这个最小响度曲线只表明了人耳可听最低的限度,现在让我们用同样的思维方式思考一下。如果要让人耳对于几个不同频率的声音感受到的响度一样,这些频率的声音要达到多少强度呢??当然,这也是可以通过实验测试出来的,综合数据,画在一个图内,又可以得出一条曲线。我们把多个不同响度的曲线放进一张图内,就是常说的等响曲线图了
一般取听觉响度为40方的这条曲线当作参考,把这条曲线倒置,就是常用的A计权网络(A声级),实践证明,不论噪声强度高还是低,A计权都能很好的反映人对噪声响度和吵闹的感觉;而且,A计权同人耳的听力损伤程度也能够对应的很好,即A声级越高,损伤也越严重。我们经常看到的耳机或者是音箱的频响曲线,都是经过A计权处理后的曲线,如果你看到哪个的曲线是很平直没有什么起伏的(特别是在高频),那么这条曲线就很可能是没有经过计权的曲线了,和实际的听感差距会很大,不能够当作参考标准。需要注意的是,等响曲线只是实验室测量少数人得出的结果。不同人的身体条件不同,对于声音的感受能力也不同,所以大部分人的听觉特征不会完全吻合等响曲线,但是大致的走向会是基本一样的,误差也不会太多。
2.时域掩蔽
时域掩蔽指的是能量较强的声音信号可以掩蔽其前或其后或同时出现的能量较弱的音频信号的现象。对于其前的声音信号的掩蔽称为超前掩蔽,其后出现的信号的掩蔽称为滞后掩蔽,同时出现的信号的掩蔽称为即时掩蔽。
即时掩蔽的作用时间与掩蔽信号的持续时间一样长,而超前掩蔽与滞后掩蔽则是即时掩蔽在时间上的延伸效果。在时间线上,越向两端延伸,效果的程度越弱。
按照常理,后出现的信号对于先出现的信号是没有掩蔽作用的,但是由于人的听觉系统还有大脑的反应滞后以及声音信号前后的关联性,使超前掩蔽也会出现。
超前掩蔽的作用时间一般很短,在20ms左右,而之后掩蔽的作用时间可以持续150ms。
举个栗子,日常生活中谈话时,如果旁边的汽车突然响起断续的鸣笛声,我们也会听不清楚对方的谈话内容
时域掩蔽主要是因为听觉系统和大脑对于声音的反应滞后产生的,所以和上面的绝对掩蔽相同,不同人的大脑反应速度不同,所以掩蔽的持续时间也不会一样
3.频域掩蔽
一个强纯音会掩蔽其附近频率同时发声的弱纯音,这种特性称为频域掩蔽。频域掩蔽就是时域掩蔽中的即时掩蔽,只是它是在频域中之研究掩蔽效应。
为了能方便理解,这里举例说明。如果一个1000Hz的纯音比另一个900Hz的纯音响度高18dB,那么900Hz的音将被1000Hz的音掩蔽,但是如果要让这个1000Hz的纯音去遮蔽距离较远的1800Hz的一个纯音的话,那么1000Hz音就必须要高出1800Hz的音45dB!实际情况下听到的声音中比较少碰到这种高出45dB的情况,频域的掩蔽效应主要集中体现在附近的频率上。
通过深入的研究实验发现,掩蔽阈值在以掩蔽信号频率为中心的一个狭小频带内是一个常数,这个狭小频带就被称为以该信号位中心的临界频带。临界频带的带宽随着中心频率的变化而变化,掩蔽效应也随之变化,这种变化是非线性的,而非线性关系在研究和表达上很不方便。研究者们使用了一个经验公式来解决这个问题,掩蔽曲线与临界频带的关系变成了线性关系。这个公式比较复杂这里就不做论述。
其实大家理解了上面三个概念以后,不难想象到有损音乐是如何对“无损”音乐进行缩减而又保持一定的音质的研究者们综合以上三个掩蔽效应,再加上一些其他因素,建立起了一个数学模型,人体听觉心理学模型(PerceptualModel)
在MP3的编码过程中,通过使用听觉心理学模型对原始无损信号进行计算,滤除掉理论上会因为掩蔽效应而听不见的信号,只留下那些会被听到的信号,这一过程就是“有损”的过程了。
有损音乐“损失”的就是上面提到的三种会被掩蔽掉的信号
通过对心理学模型的精度进行调整,可以不同程度地滤除掉信号,滤除的信号多了,虽然能减少总信息量节约空间,但是势必会造成较大的失真。
MP3的编码过程中,以CBR(固定码率)为例,规定一个数据流量(比如常见的320k
bp
s),然后从最高精度的心理学模型开始试起,进行编码,得出一个结果,然后判断这个结果的数据流量是否超过了规定的流量,如果超过了,则换下一个模型进行编码,滤除更多的信号进行尝试,知道数据流量符合规定流量。MP3编码就是这样不停地进行try and error。
MP3的编码过程还有很多很多,多相滤波分频带,子带分别输出样本,数据流包装成帧,Huffman编码进一步压缩体积。。。。等等等等
前面也说了,本文只是向大家介绍有损和无损的差别,对于这些涉及算法的知识,只能请大家自行搜索相关知识了
最后,我想说的是,不同人对于声音的感知能力不同,听觉心理学模型不能满足所有人,只能取一个居中的模型。如果某人对声音的感知能力超过了这个模型的预期,那么他就有可能听出“有损”和“无损”的差别来了。要区别出有损和无损的差别对回放设备也有要求,如果你的回放设备解码能力不佳,放大部分失真不够低,电声转换部分又有一个较大失真的话,经过这几层失真,无论原始信号是什么,等你听到都变成“有损”了,无论你听觉能力多好,也是无法分辨出无损和有损的差别的。
声音的感受能力是可以进行训练的,个人经验,就上面的时域掩蔽来说,一个训练有素的鼓手的听觉时域掩蔽效应的影响肯定不会有普通人那么大。
就欣赏音乐的角度而言,我们没有必要去刻意进行这种训练,但是我们要知道,不能因为自己听不出音质的还坏就认为别人也没有能力听出音质好坏