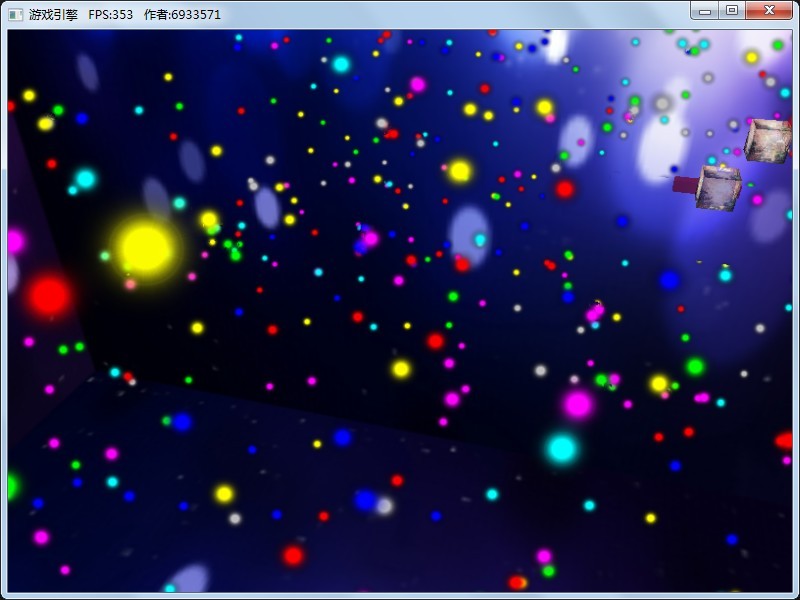
level 5



 一张FLBuffer是用来存放(深度,颜色(包含透明度)和下一个结点的地址)的结构缓存,没错,我将要使用链表,我们将为窗口中每个点创建一条链表,但仅靠它是不能完成链表的功能的,所以有第二张缓存startOffserBuffer,这是一张和窗口等大的缓存,它对应窗口上的每一个像素点,存放的是这个像素点位置上链表的起始位置,以数组的下标代替地址。
一张FLBuffer是用来存放(深度,颜色(包含透明度)和下一个结点的地址)的结构缓存,没错,我将要使用链表,我们将为窗口中每个点创建一条链表,但仅靠它是不能完成链表的功能的,所以有第二张缓存startOffserBuffer,这是一张和窗口等大的缓存,它对应窗口上的每一个像素点,存放的是这个像素点位置上链表的起始位置,以数组的下标代替地址。
 在Pass1里,我们正常写入顶点数据,但在经过PS的时候,把深度测试设置成测试但不写入,我们把数据储存到FLBuffer里面,然后使用clip(-1),因此不必解绑RenderTargetView也没关系,clip(-1)会丢弃这个像素点,不过我们已经事先把像素点存到了缓存里面,位置为从FLBuffer[0]开始存到渲染结束.....突然发现这里要讲好多东西= =蛋疼
在Pass1里,我们正常写入顶点数据,但在经过PS的时候,把深度测试设置成测试但不写入,我们把数据储存到FLBuffer里面,然后使用clip(-1),因此不必解绑RenderTargetView也没关系,clip(-1)会丢弃这个像素点,不过我们已经事先把像素点存到了缓存里面,位置为从FLBuffer[0]开始存到渲染结束.....突然发现这里要讲好多东西= =蛋疼

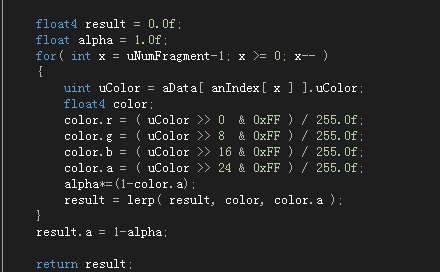 这里我也对参考的资料做了修改,原本渲染底色是黑色,现在分离透明度计算将涉及到原渲染图层底色的混合,自己做一些数学计算就能知道result.a的值是怎么得到的了,这是普通的混合插值计算,如果想要得到其他效果自己修改一下都可以实现。
这里我也对参考的资料做了修改,原本渲染底色是黑色,现在分离透明度计算将涉及到原渲染图层底色的混合,自己做一些数学计算就能知道result.a的值是怎么得到的了,这是普通的混合插值计算,如果想要得到其他效果自己修改一下都可以实现。